The Grafana Stack is the open-source ecosystem of tools maintained by Grafana Labs (and adjacent communities).
It can cover every pillar for observability:
Metrics: node-exporter + VMAgent
Logs: Loki + Promtail
Traces: Tempo + OpenTelemetry
But in this wiki, I’ll show you how to use the Grafana stack only for metrics, while using the ELK stack only for logs. The goal is to showcase different technologies commonly used in production environments, including setups where observability responsibilities are split exactly this way.
Also, each component in the stack is replaceable: you can put Prometheus where I have VictoriaMetrics, and Grafana will still visualize everything via datasources.
The stack is famously modular: pick what you need specifically.
The architecture
The whole stack consists in two machines that are on the same private LAN:
My VPS: I use it for publishing things on my domain, and in this case it is used for publishing Grafana, via nginx reverse-proxy with HTTPS.
A random VM named “vmagent”, used to scrape metrics from any other VM I want to monitor.
flowchart LR
Visitor((🌍 visitor))
subgraph LAN["🔒 Private LAN"]
subgraph VPS["☁️ VPS — farnetiandrea.it"]
NE[":9100<br/>node-exporter"]
subgraph DC["~/observability/ (docker-compose)"]
VM[":8428<br/>VictoriaMetrics"]
Graf[":3000<br/>Grafana"]
end
Nginx["🔒 nginx + certbot"]
end
subgraph NewVM["☁️ vmagent01"]
VMA[":8429<br/>VMAgent"]
end
end
VMA -- "scrape" --> NE
VMA -- "remote_write" --> VM
Graf -- "PromQL" --> VM
Visitor -- "/metrics" --> Nginx
Nginx -- "proxy_pass :3001" --> Graf
Periodically pulls the /metrics page from each target (here: just the VPS node-exporter for now), then forwards the data to the storage backend via remote_write.
The dashboard frontend. Queries VictoriaMetrics, plots graphs, organizes dashboards. Exposed publicly via nginx reverse-proxy at farnetiandrea.it/metrics.
For deploying your Grafana Stack, we’ll follow this order:
node-exporter setup on every machine where you need metrics (in my case only my VPS): we have to curl localhost:9100/metrics and see the metrics.
VictoriaMetrics setup only in one dedicated machine (in my case on my VPS as a Docker container): we need to have a empty DB ready to receive data.
VMAgent setup (on the vmagent VM): it scrapes the metrics from the machines where we installed our node-exporter, and writes them to VictoriaMetrics.
Grafana dashboard setup only in one dedicated machine (in my case on my VPS as a Docker container), exposed at /metrics.
Why this instead of “all in one”?
A single VPS with node-exporter + VMAgent + VictoriaMetrics + Grafana is totally doable and would work for a homelab, but separating the scraper onto a different host is the realistic pattern you’ll find in any company with more than a couple of servers:
The scraper (VMAgent) is the only piece that needs network access to every monitored target, so putting it on a dedicated, minimal VM makes the security perimeter small and clear.
Any other machine just needs to expose metrics, so that the scraper can harvest them.
Of course, the VictoriaMetrics database and the Grafana dashboard could also have been separated onto different machines, but that part is relatively trivial to understand.
The scraper layer, however, becomes essential once you start dealing with infrastructures of 2000+ machines: you need multiple dedicated scraper nodes to distribute the workload properly. That’s why I wanted to separate it here as well, to better distinguish its role and to show you how a scalable infrastructure is typically designed.
1. Node-exporter setup
Here we are, ready to configure our node-exporter in any VM where we need metrics.
Super simple.
First thing first, we bind the service to our private LAN, then we restrict access even more by configuring our firewall accordingly:
0. Hardening
By default node-exporter listens on all interfaces (0.0.0.0:9100).
On a server with a public IP, that means anyone on the Internet can do curl http://<your-public-ip>:9100/metrics and read:
All your mount points and disk usage
All your network interfaces and IPs
All your running processes (if the --collector.processes flag is enabled)
Last reboot time, uptime, hardware info, kernel version
That’s a leak.
Two complementary fixes: apply both for defense in depth.
1. Binding to LAN only
Edit the package defaults file:
nano /etc/default/prometheus-node-exporter
Change the ARGS line to bind to the VPS’s private LAN IP (use ip -br -c a to find it — it’s the address on your internal LAN interface, not the public one):
ARGS="--web.listen-address=<VPS_PRIVATE_IP>:9100"
Then restart:
systemctl restart prometheus-node-exporter
Verify the listen address has changed:
ss -tlnp | grep 9100
You should now see node-exporter bound only to the private IP (e.g. 10.0.0.5:9100), not 0.0.0.0:9100. From the public interface, port 9100 is now invisible — no more curl <public-ip>:9100/metrics from anywhere on the Internet.
2. Firewall rule
Even with the bind restricted, add an explicit firewall rule so that if the bind config ever drifts (you remove the flag, package update overwrites it, …) the leak doesn’t reappear.
With iptables (typical Ubuntu server setup, persisted by netfilter-persistent):
# Allow scrape from the LAN (vmagent01) — adjust to your scraper's IPiptables -A INPUT -p tcp --dport 9100 -s <VMAGENT01_PRIVATE_IP> -j ACCEPT# Drop from anywhere else (your default INPUT policy should already be DROP,# this is an explicit safety net)iptables -A INPUT -p tcp --dport 9100 -j DROP# Persist the rule across rebootsnetfilter-persistent save
After this, only vmagent01 (via its LAN IP) can reach :9100. The wider Internet sees nothing.
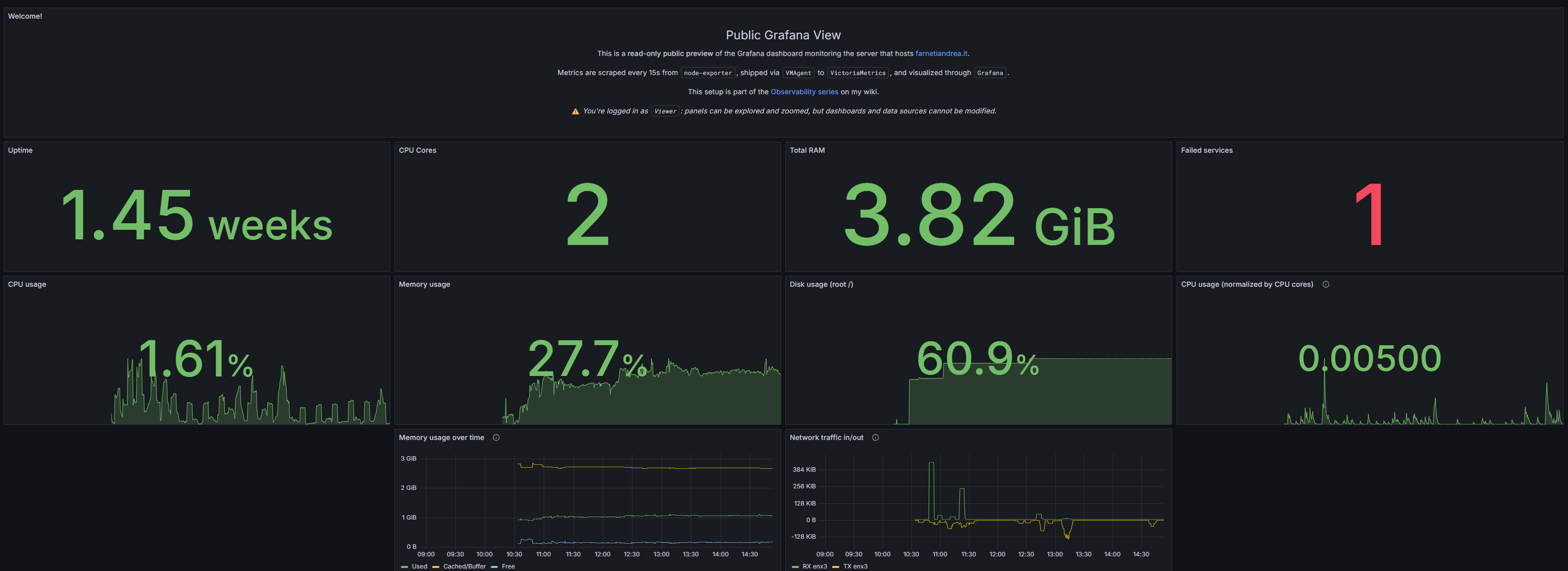 https://farnetiandrea.it/metrics
https://farnetiandrea.it/metrics